Table of contents
New tablizer release v1.6.0
I started to work on tablizer three years ago and lots of new features and changes have accumulated since. So, here’s the update due.
First of all, I migrated the repo toe Codeberg and left Github behind because Microsoft supports Trump and supporting Trump means to support a fucking fascist asshole. And MS scrapes every repo there to feed their incarnation of the “AI” bubble, Copilot, to which I decline to consent.
So let’s look at some of the innovations since 2022:
Help and Documentation
There’s now a short and detailed help. The short help is shown when
you use the parameter -h or when there’s some usage error. As of
v1.6.0 it looks like this:
$ tablizer -h
tablizer [regex,...] [-r file] [flags]
-c col,... show specified columns -L colorize rows
-k col,... sort by specified columns -j read JSON input
-F col=reg filter field with regexp -v invert match
-T col,... transpose specified columns -n numberize columns
-R /from/to/ apply replacement to columns in -T -N do not use colors
-y col,... yank columns to clipboard -H do not show headers
--ofs char output field separator -s specify field separator
-r file read input from file -z use fuzzy search
-f file read config from file -I interactive filter mode
-x col,... use custom headers -d debug
-o char use char as output separator -g auto generate headers
-K /pattern/foreground[:background]/ colorize pattern of output
-O org -C CSV -M md -X ext -S shell -Y yaml -J json -P template
-a sort by age -i sort numerically -t sort by time -D sort descending order
-m show manual -v show version --help show detailed help
The detailed help is shown, when you ask for it using --help, which
is much longer these days, hence the short help:
$tablizer --help
Manipulate tabular output of other programs
Usage:
tablizer [regex,...] [-r file] [flags]
Operational Flags:
-c, --columns string Only show the speficied columns (separated by ,)
-v, --invert-match select non-matching rows
-n, --numbering Enable header numbering
-N, --no-color Disable pattern highlighting
-H, --no-headers Disable headers display
-s, --separator <string> Custom field separator (maybe char, string or :class:)
-k, --sort-by <int|name> Sort by column (default: 1)
-z, --fuzzy Use fuzzy search [experimental]
-F, --filter <field[!]=reg> Filter given field with regex, can be used multiple times
-T, --transpose-columns string Transpose the speficied columns (separated by ,)
-R, --regex-transposer </from/to/> Apply /search/replace/ regexp to fields given in -T
-K --regex-colorizer /from/color/ colorize pattern of output (color: fg[:bg])
-j, --json Read JSON input (must be array of hashes)
-I, --interactive Interactively filter and select rows
-g, --auto-headers Generate headers if there are none present in input
-x, --custom-headers a,b,... Use custom headers, separated by comma
Output Flags (mutually exclusive):
-X, --extended Enable extended output
-M, --markdown Enable markdown table output
-O, --orgtbl Enable org-mode table output
-S, --shell Enable shell evaluable output
-Y, --yaml Enable yaml output
-J, --jsonout Enable JSON output
-C, --csv Enable CSV output
-A, --ascii Default output mode, ascii tabular
-P, --template <tpl> Enable template mode with template <tpl>
-L, --hightlight-lines Use alternating background colors for tables
-o, --ofs <char> Output field separator, used by -A and -C.
-y, --yank-columns Yank specified columns (separated by ,) to clipboard,
space separated
Sort Mode Flags (mutually exclusive):
-a, --sort-age sort according to age (duration) string
-D, --sort-desc Sort in descending order (default: ascending)
-i, --sort-numeric sort according to string numerical value
-t, --sort-time sort according to time string
Other Flags:
-r --read-file <file> Use <file> as input instead of STDIN
--completion <shell> Generate the autocompletion script for <shell>
-f, --config <file> Configuration file (default: ~/.config/tablizer/config)
-d, --debug Enable debugging
-h, --help help for tablizer
-m, --man Display manual page
-V, --version Print program versionAs you might already know, tablizer has a manual page as well, which
can be read when the parameter --man has been supplied. In earlier
versions, the text was piped into the external program more. Today
we’re using our own builtin tui pager based on bubbletea
viewport.
Input processing
Tablizer accepts a wide range of tabular input formats, which you can
split using the -s option, which also accepts a regular
expression. While this is a powerful feature, not everyone is familiar
with regexes. Therefore you can use pre-defined split regexes:
:tab:Matches a tab and eats spaces around it.:spaces:Matches 2 or more spaces.:pipe:Matches a pipe character and eats spaces around it.:default:Matches 2 or more spaces or tab. This is the default separator if none is specified.:nonword:Matches a non-word character.:nondigit:Matches a non-digit character.:special:Matches one or more special chars like brackets, dollar sign, slashes etc.:nonprint:Matches one or more non-printable characters.
Beside tabular input you may also use JSON input, which must consist
of an array of hashes using the -j option.
The processing of file input has changed as well. Previously you could
specify a pattern and one or more files and tablizer attempted to
determine which was what. But this was cumbersome and errorprone code
and I ditched it. To specify a file to read from, use the option -r
now.
Table Headers
Previously headers has just been numberized and to tell tablizer to use a header, you had to supply it’s number. This has been completely overhauled.
First of all, header numbering is still there and these numbers can
still be used, but it’s not being displayed by default anymore. If you
want to see numberized headers, add the -n option, which now enables
it.
However, in most of cases you’ll not need it and can just refer to the header names. Let’s look at some examples, shall we?
Given the following CSV file (which we’ll tabularize using -s,):
$ cat t/testtable6.csv
Date,Account Number,Subject,Amount
20250101,968723487,Dogs Medication Invoice 9919292,-450.00
20250103,172747812,Tax return tax id HHD813D/12564H,+912.14
20250105,987122711,Car repair order 020123,-299.45
20250108,731217273,Rent - 12234 Sunset Blvd,-2960.00
we can reduce the number of displayed columns with -c:
$ cat t/testtable6.csv | tablizer -s, -cdate,acc.*,amount
Date Account Number Amount
20250101 968723487 -450.00
20250103 172747812 +912.14
20250105 987122711 -299.45
20250108 731217273 -2960.00
So, -c expects a comma-separated list of column names (case
insensitive) and it supports regular expressions as well, which is
very handy if there are particular long names etc.
However, you can still use numbers and you can even mix them:
$ cat t/testtable6.csv | tablizer -s, -cdate,acc.*,4
Date Account Number Amount
20250101 968723487 -450.00
20250103 172747812 +912.14
20250105 987122711 -299.45
20250108 731217273 -2960.00
Sometimes you’ll have input without headers. Let’s simulate it by removing the headers of our CSV input:
$ grep -v Date t/testtable6.csv | tablizer -s, -g -c1,3
1 3
20250101 Dogs Medication Invoice 9919292
20250103 Tax return tax id HHD813D/12564H
20250105 Car repair order 020123
20250108 Rent - 12234 Sunset Blvd
The option -g (--auto-headers) generates numberized headers when
specified. Everything else can be done using these numbers.
However, these numbers look awkwards, especially if you want to use the output to generate a report to be sent to upper management or the like. In such cases you can use specify custom headers instead:
$ grep -v Date t/testtable6.csv | tablizer -s, -x Datum,Kontonummer,Verwendungszweck,Betrag -cdatum,betrag
Datum Betrag
20250101 -450.00
20250103 +912.14
20250105 -299.45
20250108 -2960.00
Here I have used german headers.
Cell Filtering
A couple of new possibilities to filtering of cells have been added since 2022. It was already possible to filter rows using a regular expression as program argument.
Today you can filter by singular cells (or fields) using the -F option. It takes
a field name as argument with a regular expression like:
-F 'field=regexp'
A good example for the benefit of this feature for example is a table like this:
$ cat table
ID VERSION STATUS
3cc7b723-7cad-485e-9612-327470df3908 13 Running
727eb035-8678-43e4-b144-f4024cc4db07 13 Running
96377897-66bf-4226-8c8a-dd07c351140c 15 Running
a0bb2d7c-6e67-48e6-9162-4c4c5054c820 14 Running
e91778cf-5474-492e-9a14-70298732c300 15 Running
f16caf54-b488-4c58-9d70-140412f6aa62 16 Running
Now, when you want to get a list of rows with version 14 and use the pattern argument, you’ll get:
$ cat table | tablizer 14
ID VERSION STATUS
727eb035-8678-43e4-b144-f4024cc4db07 13 Running
96377897-66bf-4226-8c8a-dd07c351140c 15 Running
a0bb2d7c-6e67-48e6-9162-4c4c5054c820 14 Running
e91778cf-5474-492e-9a14-70298732c300 15 Running
f16caf54-b488-4c58-9d70-140412f6aa62 16 Running
Not, what we wanted, because the string 14 matches other parts of
the rows and we didn’t get only rows with version 14. To achieve this,
do:
$ cat table | tablizer -Fversion=14
ID VERSION STATUS
a0bb2d7c-6e67-48e6-9162-4c4c5054c820 14 Running
You can use the option multiple times and negation is possible as well, e.g.:
$ cat table | tablizer -Fversion!=15
ID VERSION STATUS
3cc7b723-7cad-485e-9612-327470df3908 13 Running
727eb035-8678-43e4-b144-f4024cc4db07 13 Running
a0bb2d7c-6e67-48e6-9162-4c4c5054c820 14 Running
f16caf54-b488-4c58-9d70-140412f6aa62 16 Running
Interactive Filtering
This is a really fun feature! From time to time I stumbled upon a
situation, where neither row filter or cell filter were successful to
filter the rows I wanted. Therefore there’s now an interactive filter
invoked with the option -I:

Here you can see the interactive mode in action. The help is being
shown (normally it is hidden, show it with the ? key). As you can
see you can filter, sort and manually select rows. Pretty handy!
Cell Modification
Sometimes you might need to modify certain cell contents. Of course
you can use external tools such as sed or sd. However, due to the
nature of tabular output, patterns to replace just the content of a
cell might get very complicated. You can also use the venerable
teip to work on cell level, which is
a very powerful tool.
However, for small manipulations you can use the new builtin options
-R and -T. The option -T marks the columns on which to operate
and -R specifies the search/replace operation. Multiple
manipulations can be applied.
Given the following CSV input:
$ cat t/testtable6.csv
Date,Account Number,Subject,Amount
20250101,968723487,Dogs Medication Invoice 9919292,-450.00
20250103,172747812,Tax return tax id HHD813D/12564H,+912.14
20250105,987122711,Car repair order 020123,-299.45
20250108,731217273,Rent - 12234 Sunset Blvd,-2960.00
We want to modify the date format:
$ cat t/testtable6.csv | tablizer -s, -Tdate -R '/(....)(..)(..)/$1-$2-$3/'
Date Account Number Subject Amount
2025-01-01 968723487 Dogs Medication Invoice 9919292 -450.00
2025-01-03 172747812 Tax return tax id HHD813D/12564H +912.14
2025-01-05 987122711 Car repair order 020123 -299.45
2025-01-08 731217273 Rent - 12234 Sunset Blvd -2960.00
As you can see, only the Date column has been touched, not any other
columns.
More output options
You can now output the tabular data as JSON (an array of objects).
And there’s an option to use templates, which makes it flexible to create any output you like.
For example:
$ cat t/testtable6.csv | tablizer -s, --template "{{ .amount }} dollars have been transfered on {{ .date }}."
-450.00 dollars have been transfered on 20250101.
+912.14 dollars have been transfered on 20250103.
-299.45 dollars have been transfered on 20250105.
-2960.00 dollars have been transfered on 20250108.
The template syntax is the builtin template language of GO. It also supports the Sprig template functions. Together this is a very powerful toolset. You can create almost any output format with this like HTML or Latex.
The template is applied to every row. To access a field, use the lowercase field (column) name. Numberized field names are not supported in templates. A newline is appended after each template output.
Colors
From the start tablizer has highlighted matching strings in the output using colors.
A new option -L highlights the rows in an alternating color:

You can also highlight parts of the output using regular expressions
using the -K option. For instance:
$ cat t/testtable6.csv | tablizer -s, -K '/-[0-9\.]+/white:red/' -K '/\+[0-9\.]+/white:green/'

The parameter to -K has the same syntax as -R but the replacement
string must be a color as available by the color
module. By default the specified
color will be used as foreground color. You can add a background color
after a colon as in our example above.
Colorization can be turned off with the option -N or by setting the
environment variable NO_COLORS=1.
The Bottom Line
So, lots of things have changed in the past years and more might come in the future as I am using the tool myself daily privately and at work.
If you want to give it a try, go to the tablizer release page and download a release binary for your platform. For feedback or bugs, use the issue tracker.
Prior Art
Last but not least I want to show you some alternatives (from the README):
miller
This is a really powerful tool to work with tabular data and it also allows other inputs as json, csv etc. You can filter, manipulate, create pipelines, there’s even a programming language builtin to do even more amazing things.
csvq
Csvq allows you to query CSV and TSV data using SQL queries. How nice is that? Highly recommended if you have to work with a large (and wide) dataset and need to apply a complicated set of rules.
goawk
Goawk is a 100% POSIX compliant AWK implementation in GO, which also
supports CSV and TSV data as input (using -i csv for example). You
can apply any kind of awk code to your tabular data, there are no
limit to your creativity!
teip
I particularly like teip, it’s a real gem. You can use it to drill “holes” into your tabular data and modify these “holes” using small external unix commands such as grep or sed. The possibilities are endless, you can even use teip to modify data inside a hole created by teip. Highly recommended.
↷ 20.01.2026 🠶 #golang #opensource #terminal #tui #cli #commandline ⤒
New release of epuppy: 0.0.8
A new relase of epuppy is available: epuppy version 0.0.8.
It fixes a bug with broken page breaks when reading epub files created with mobitool.
There’s also a new flag: --create-config which creates a new config file with the default values, which makes it easier to configure epuppy.
↷ 05.01.2026 🠶 #golang #epub #ebook #reader #terminal #tui ⤒
epuppy - a simple but comfortable terminal epub reader
Epuppy is a simple yet comfortable epub reader for the terminal written in Go. The idea behind this tool is to be able to just take a look into some epub file without the need to leave the shell. And it had to be fast enough to just peak into an ebook. However, it is possible to actually read epub ebooks with epuppy but I’d encourage you to buy a hardware ebook reader with an e-ink display. It’s better for your eyes in the long run.
It has a couple of usefull features like:
- light and dark mode
- customizable colors
- adjustable text width
- it is possible to store the reading position
- it can display cover images if supported by your terminal
- you can also just dump the ebook contents to stdout for further processing

Visit the project page on codeberg for more details and download options.
↷ 03.01.2026 🠶 #golang #epub #ebook #reader #terminal #tui ⤒
Moved from Github to Codeberg

I have finally moved all my opensource projects from github to codeberg.
There are multiple reasons:
Privacy Protection
Today Github is owned by Microsoft and as such prone to US government overreach. The US government could order Microsoft to reveal data of their customers and they would happily comply, wether lawful or not, as they did lots of times in the past.
Trump Dictatorship
I am trying to reduce my usage of US products and services as much as I can, because I don’t want to support a dictatorship. Although I could live with some services or products from such states, the US case is a special one because of Trump’s open hostility towards the EU, our freedoms, our rights, our laws and our way to live in general.
Also big IT corporations like Amazon, Microsoft or Google comply willingly with the Trump regime, their owners even donate huge amounts of money to Trump and his supporters. They are accomplice or partners in crime with the Trump regime and the coming dictatorship. I don’t want to use services made by criminals.
Generative AI
The current “AI” bubble affects most corporations, Microsoft and thus Github included. They ignore copyrights of authors, artists and scientists, they really don’t give a shit about the rights of anyone and they don’t give a shit about the environment which they destroy with their incredible hunger for energy.
And although there might be some useful uses of LLMs, in most cases it’s just being used for bullshit, to further enshittificate already bad services, to siphon more data and to to spy on us. “AI” is a fascistic enterprise.
Github rolls their own incarnation of this shit: CoPilot. It ingests the sourcecode of hundreds of thousands developers, ignores their license terms and produces scrap code, which doesn’t even work in most cases. Many Projects already start to develop “AI Policies” to fight the flood of nonsense pull requests by “AI Coders” (i.e. bots).
I don’t want CoPilot to ingest my code and spit out code snippets for those morons using it without any hint to the GPL or my authorship. This is not the way opensource is supposed to work!
Moved
So, I moved to codeberg. In addition I am also a supporting member of the Codeberg e.V.
My repositories on github still exist and will remain there for a while so that users are still able to find them there. Each repo contains a deprecation warning pointing to codeberg and the repos are archived. I created a branch which only contains the README in every repo which is now the default branch on github. The main branch containing the actual code still exists, but will be removed later as well.
See Also
↷ 18.12.2025 🠶 #github #codeberg #opensource #repository #unplugtrump ⤒
Managing hugo with git and ssh on android
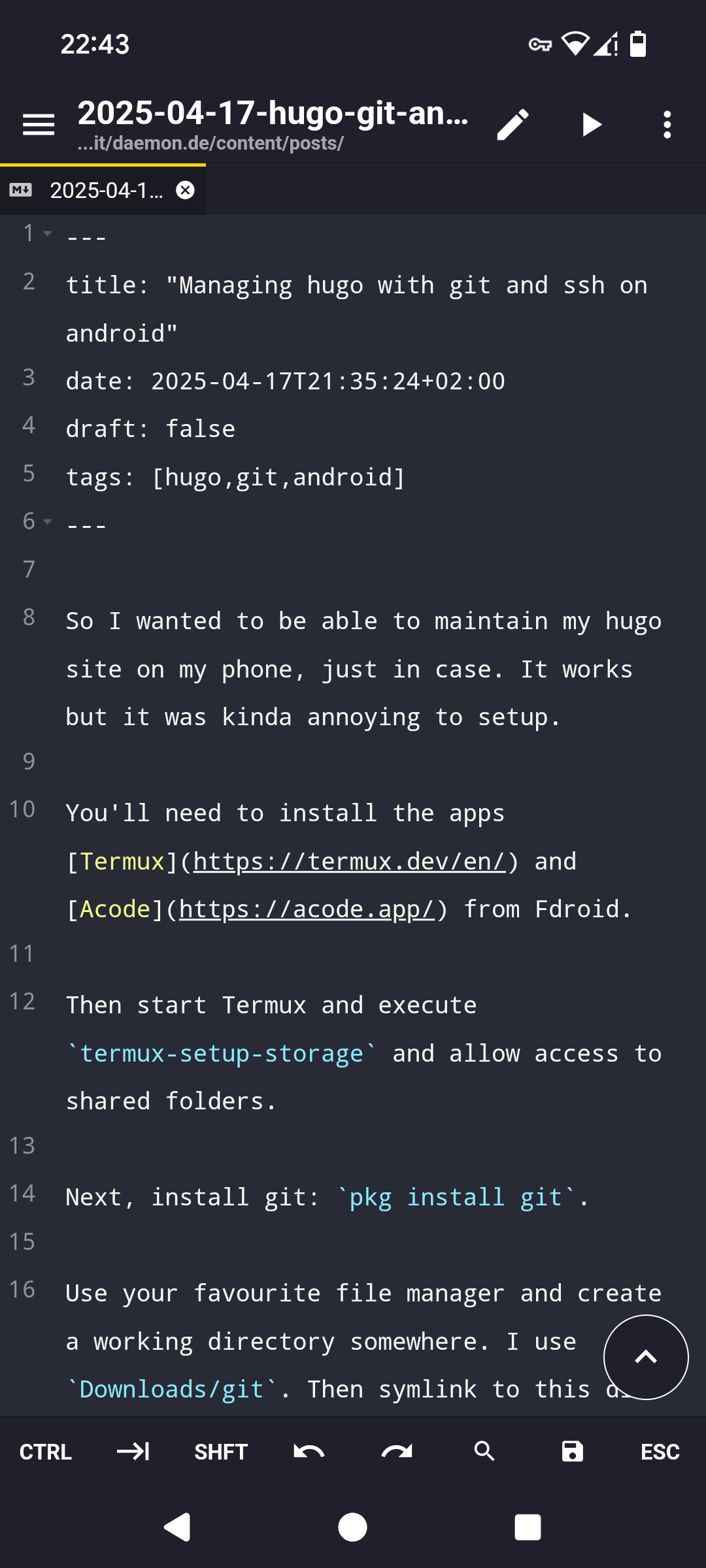
So I wanted to be able to maintain my hugo site on my phone, just in case. It works but it was kinda annoying to setup.
You’ll need to install the apps Termux and Acode from Fdroid.
Then start Termux and execute termux-setup-storage and allow access to shared folders.
Next, install git: pkg install git.
Use your favourite file manager and create a working directory somewhere. I use Downloads/git. Then symlink to this dir in Termux:
ln -s /storage/emulated/0/git .
Now, generate a new SSH key pair:
ssh-keygen -t ed25519
Install the public key to your repository. I am using Gitolite, so I added it to the keydir in the gitolite-admin dir.
That’s basically it. Clone your repo, open the folder with Acode, edit or add files and commit and push them to your git repo.
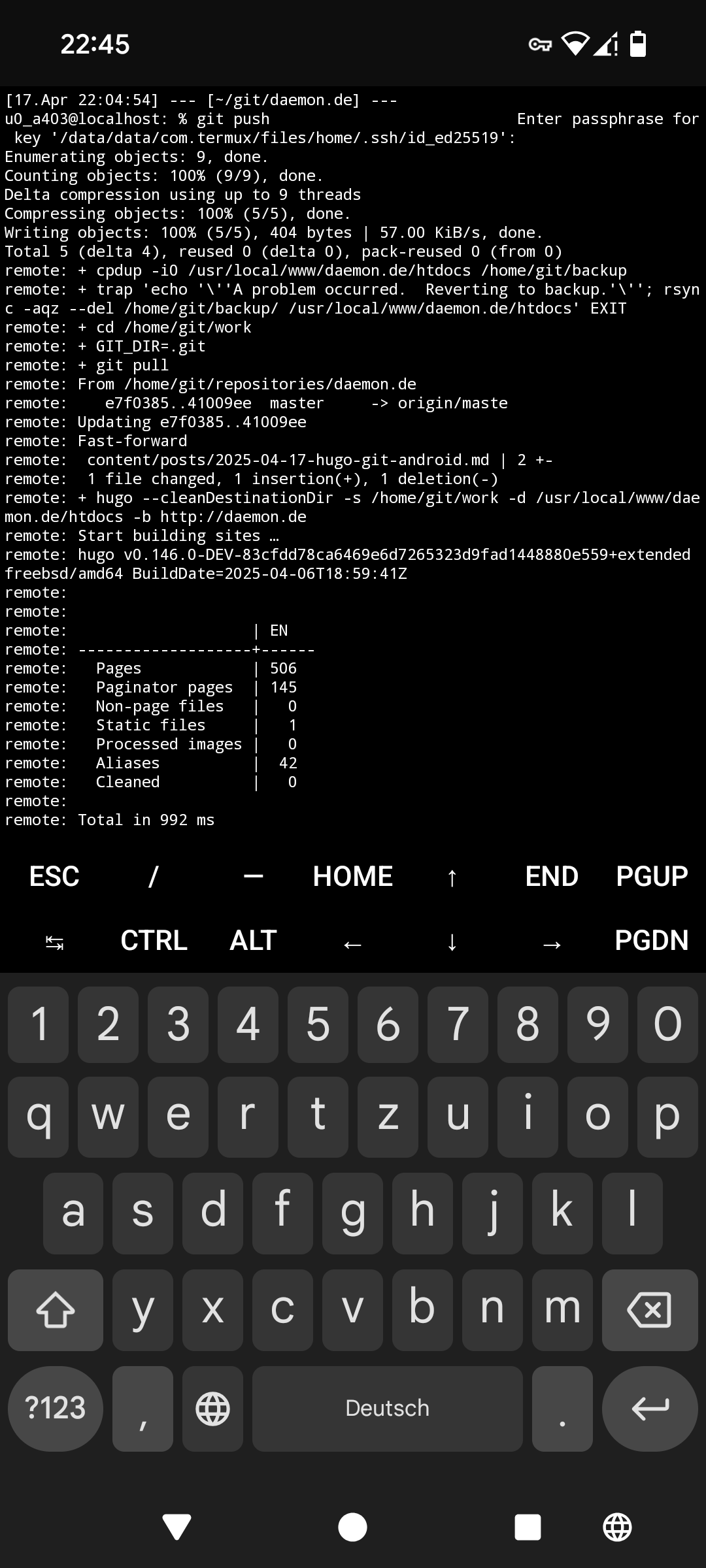
I’ll not describe, how to setup gitolite and the hugo repo, maybe in a follow-up post.